
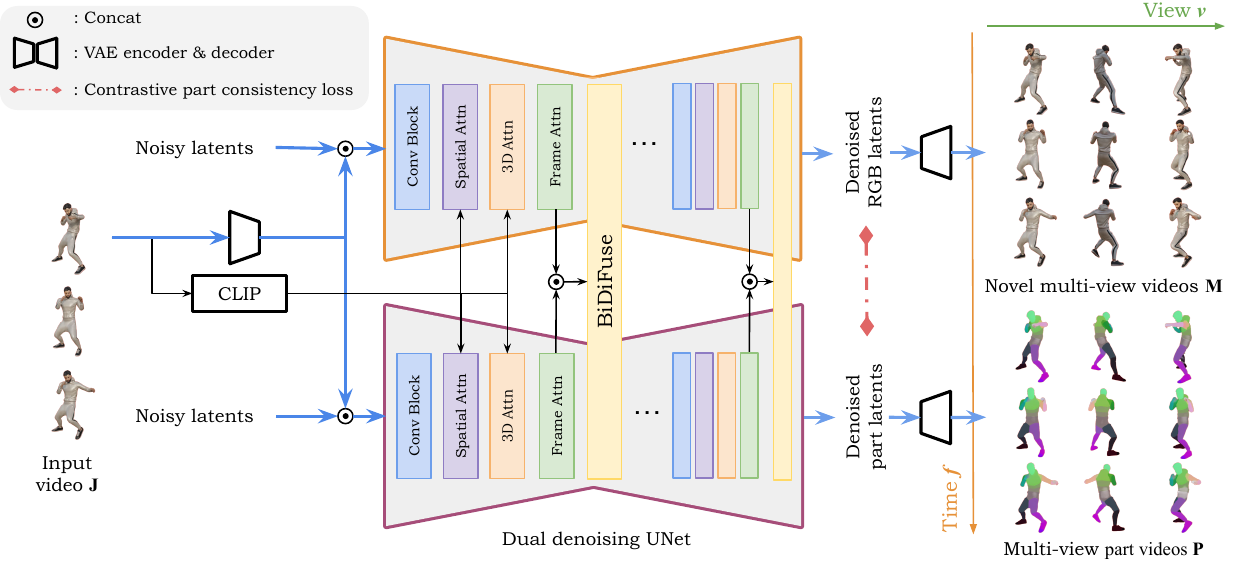




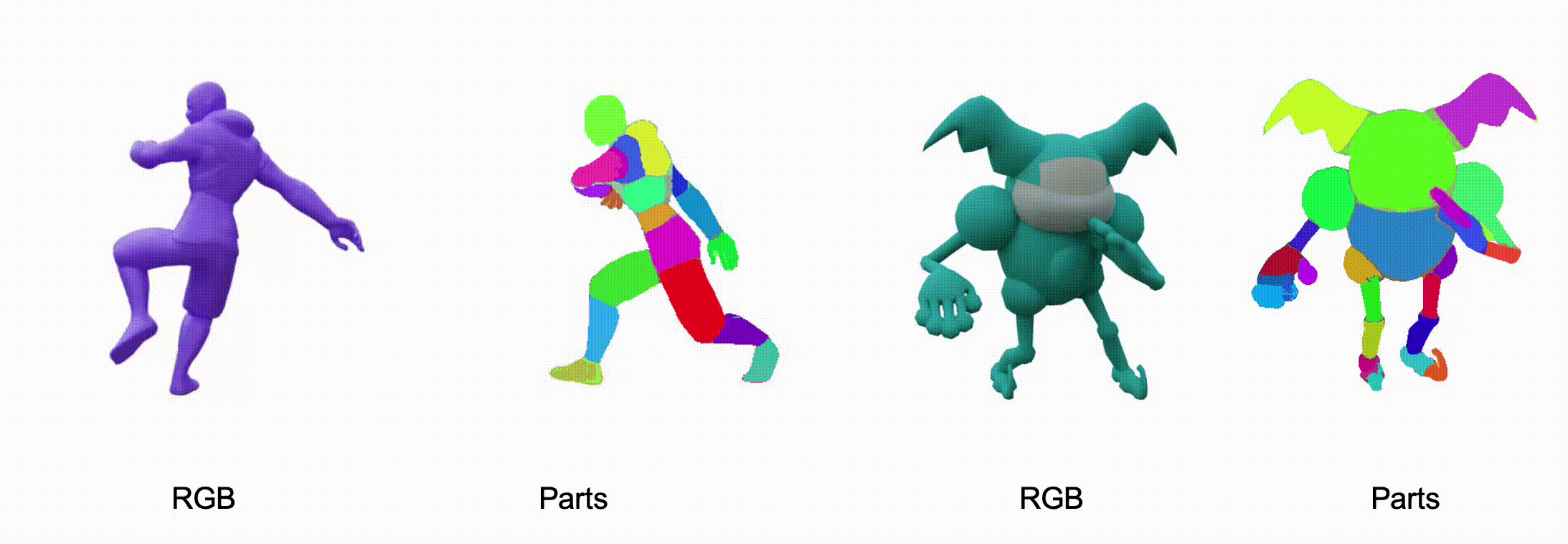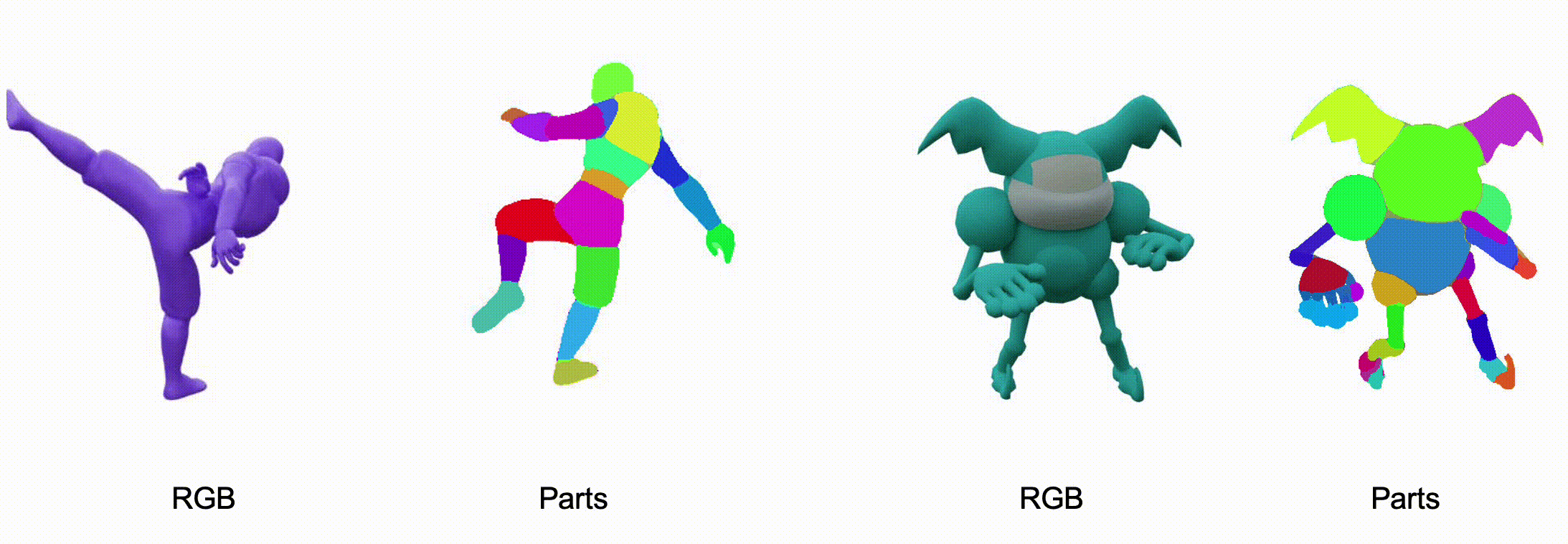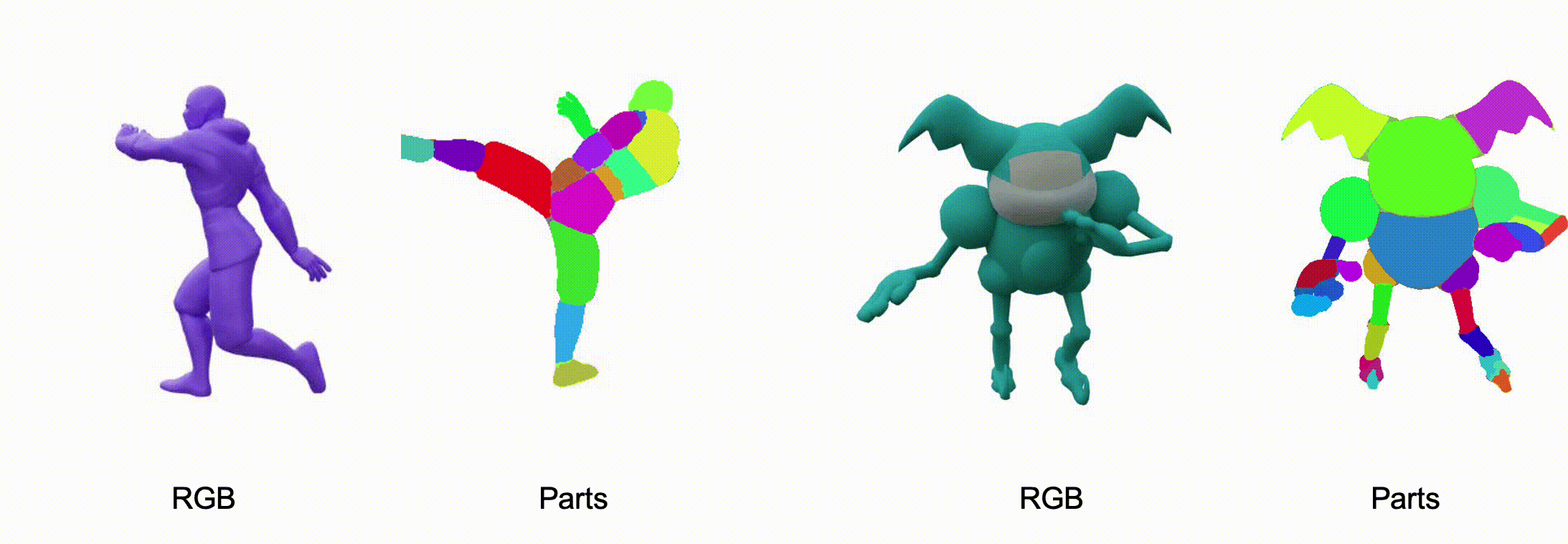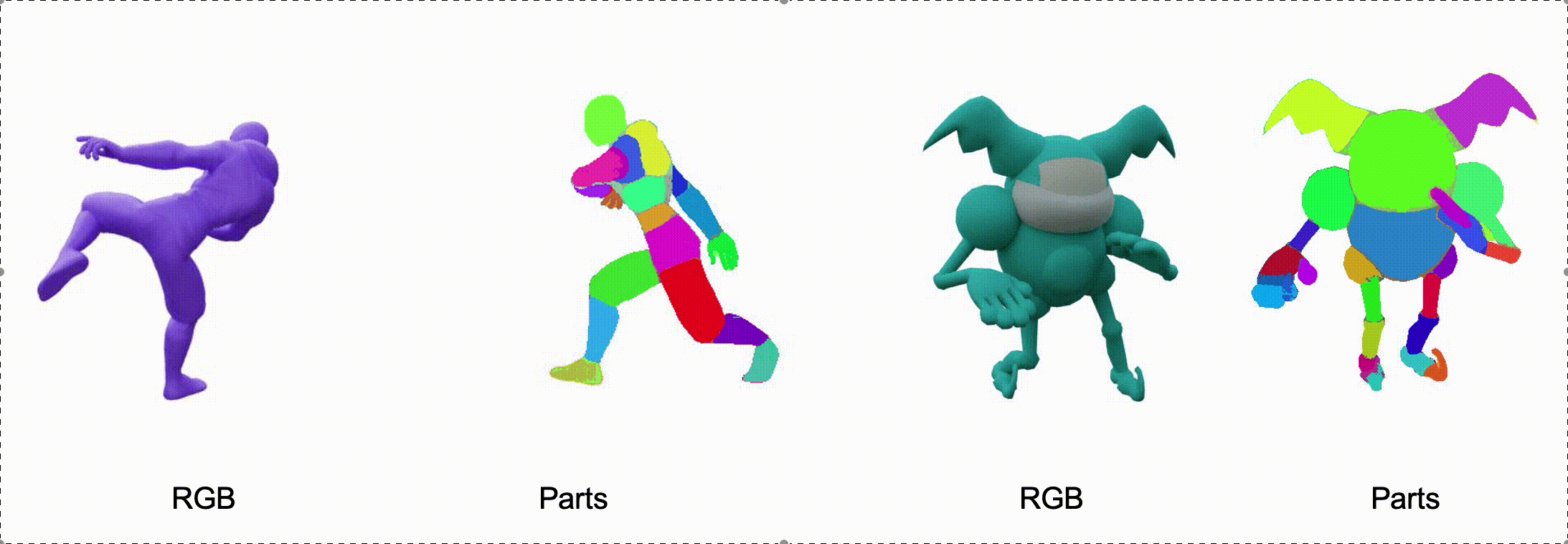

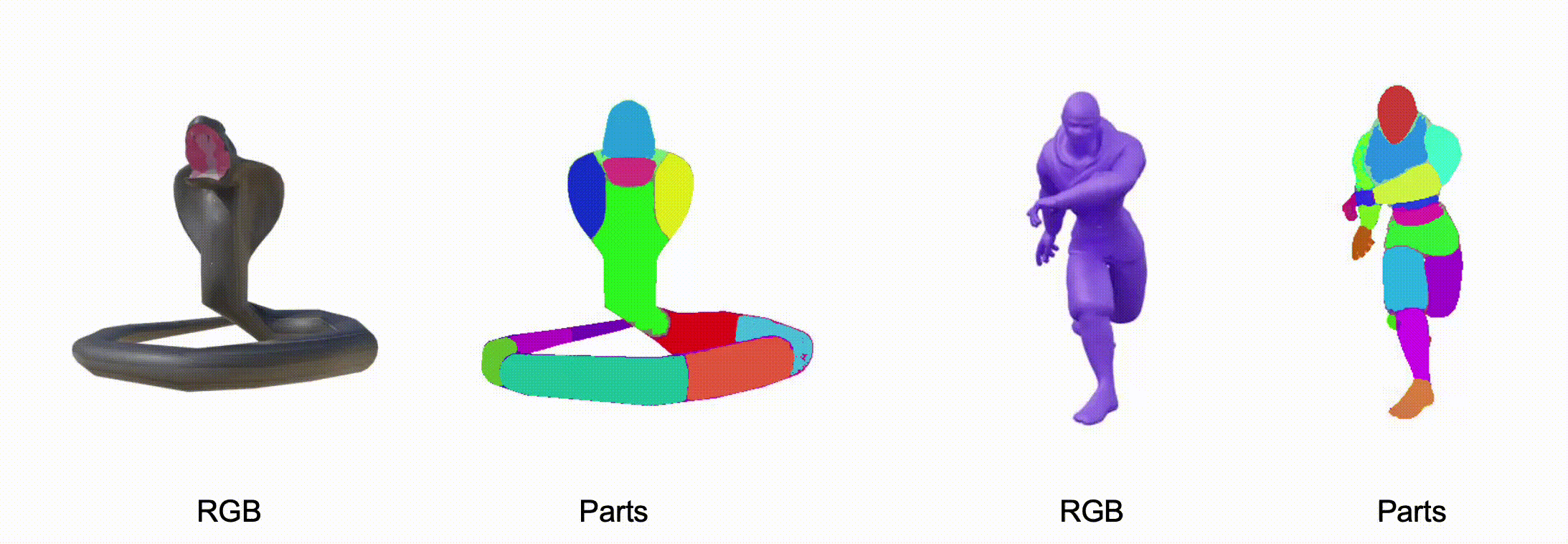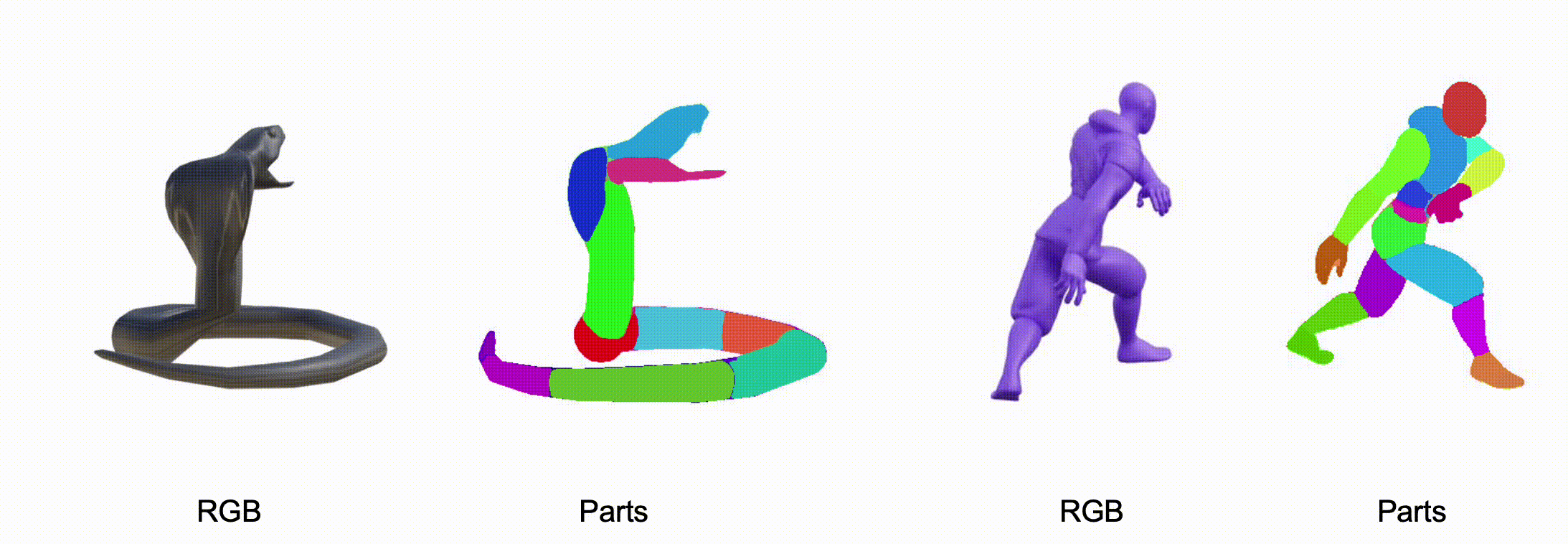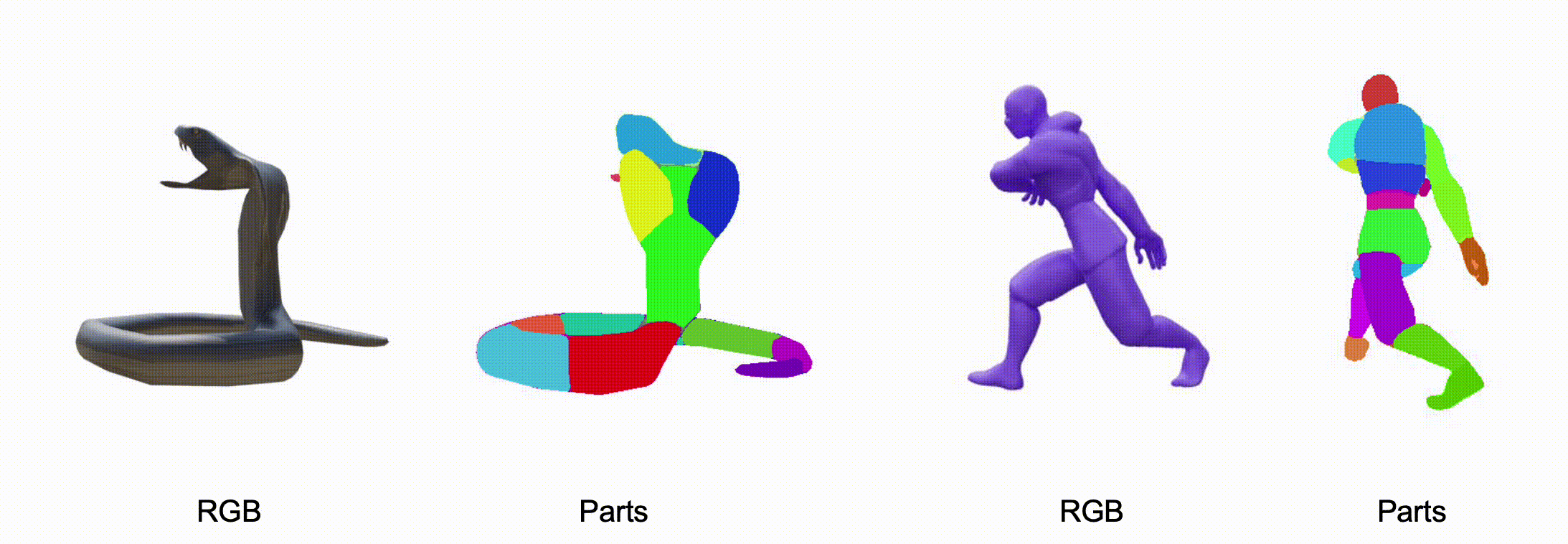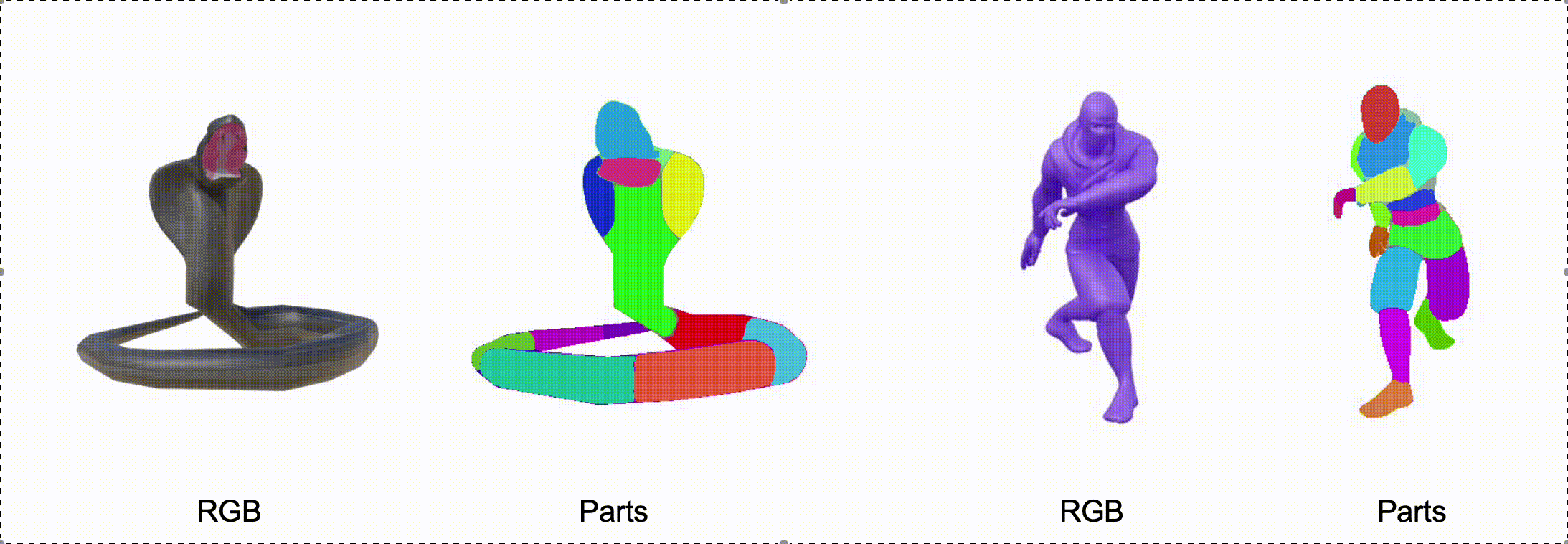
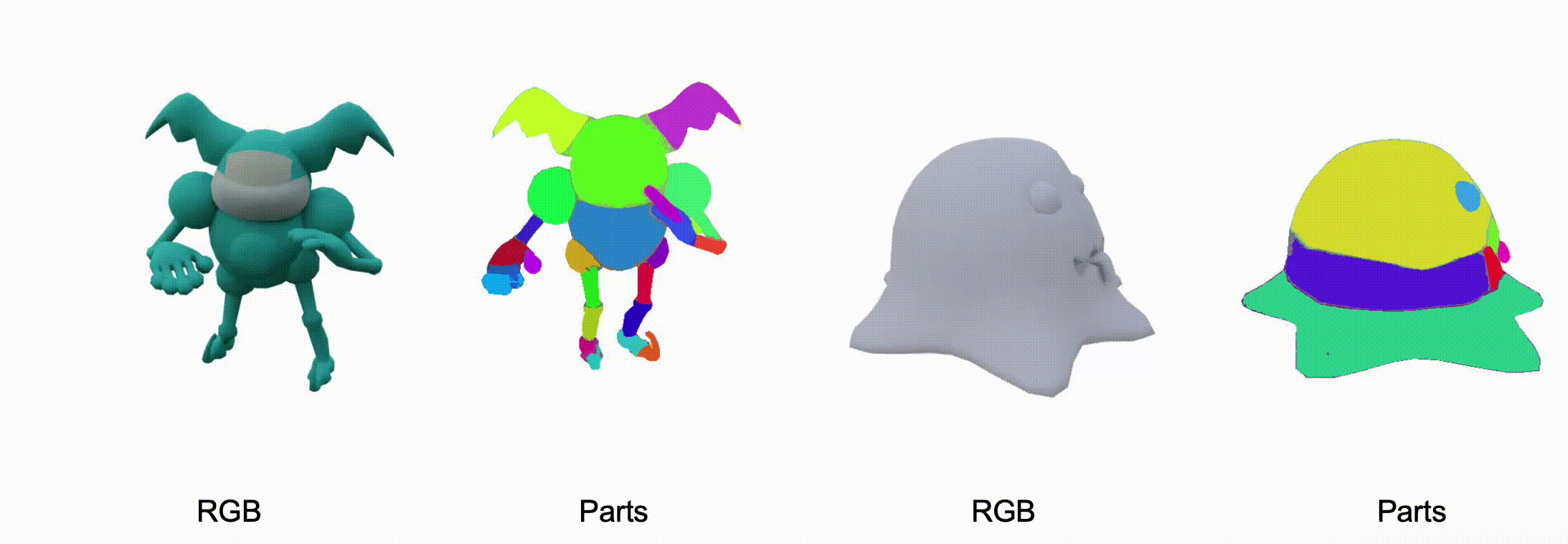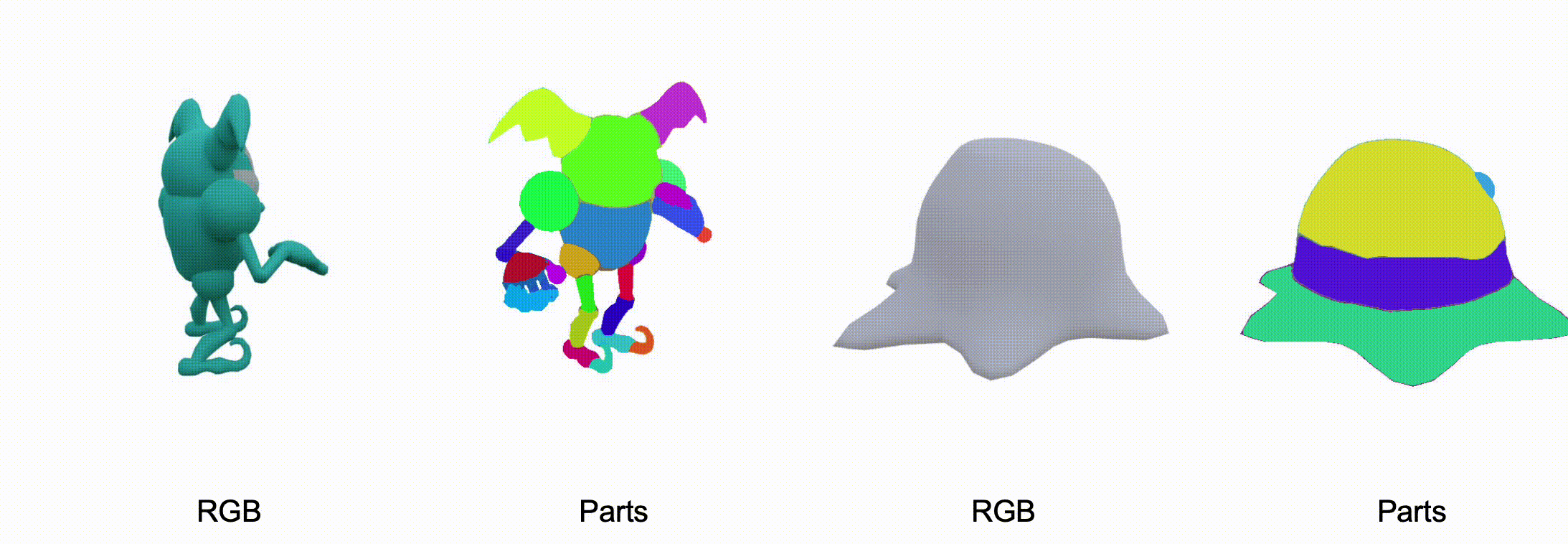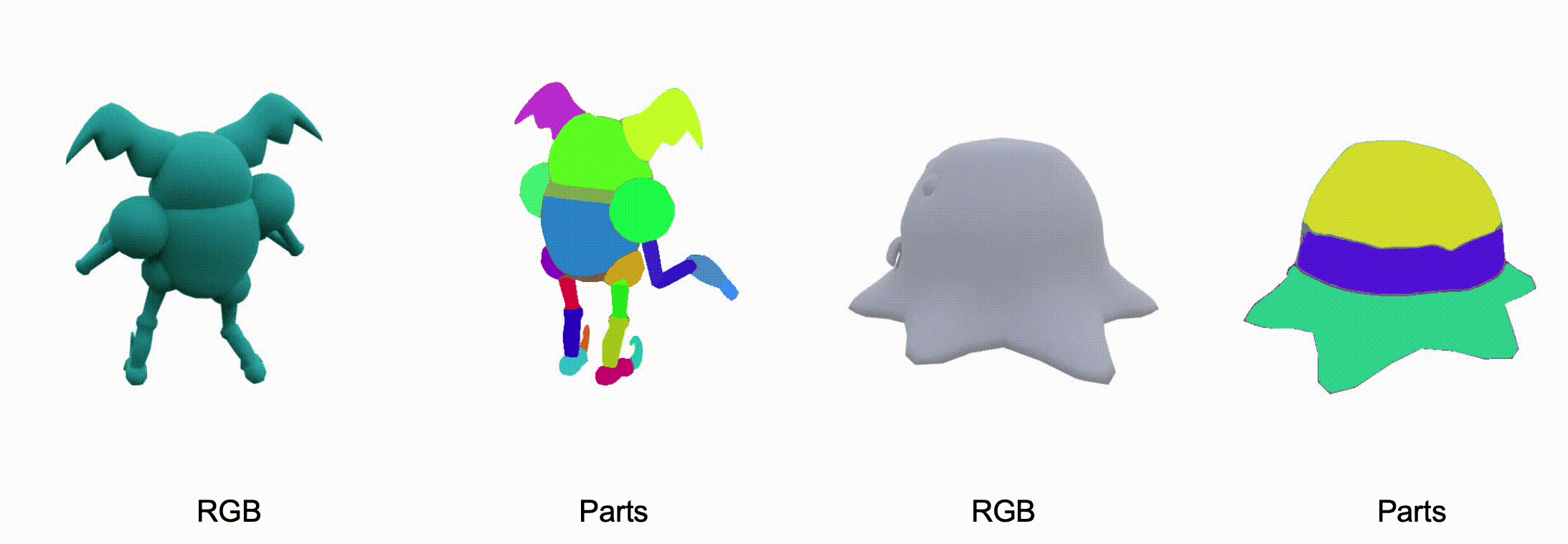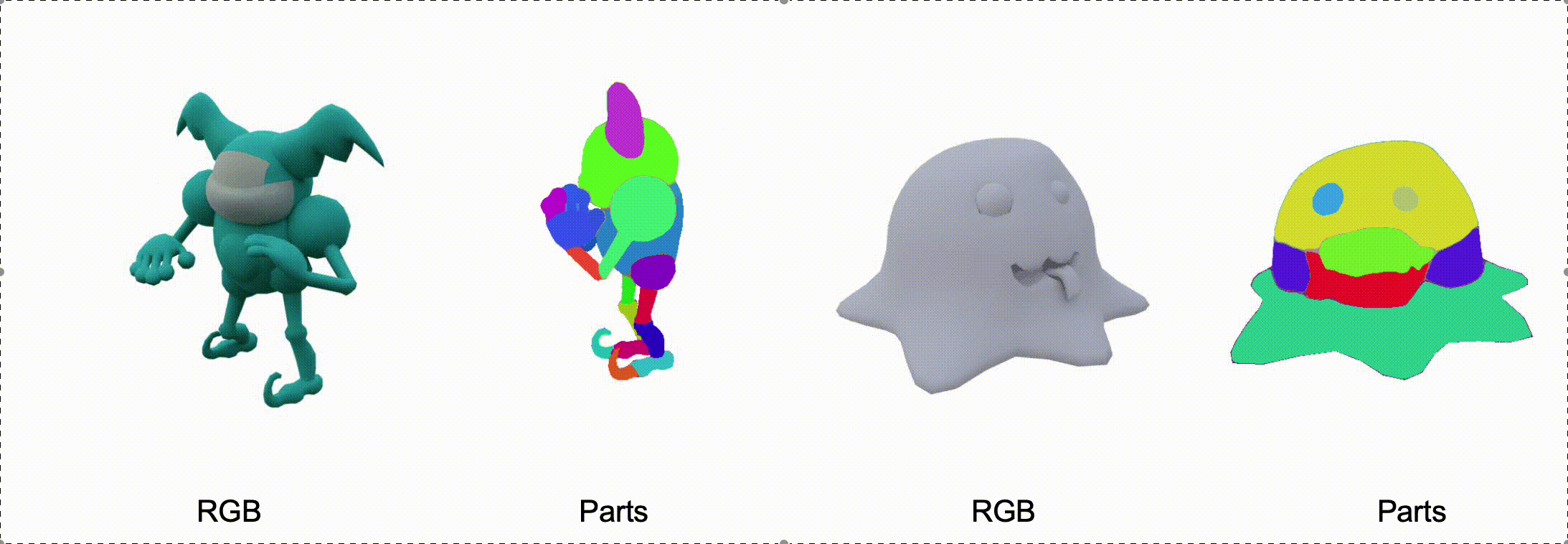
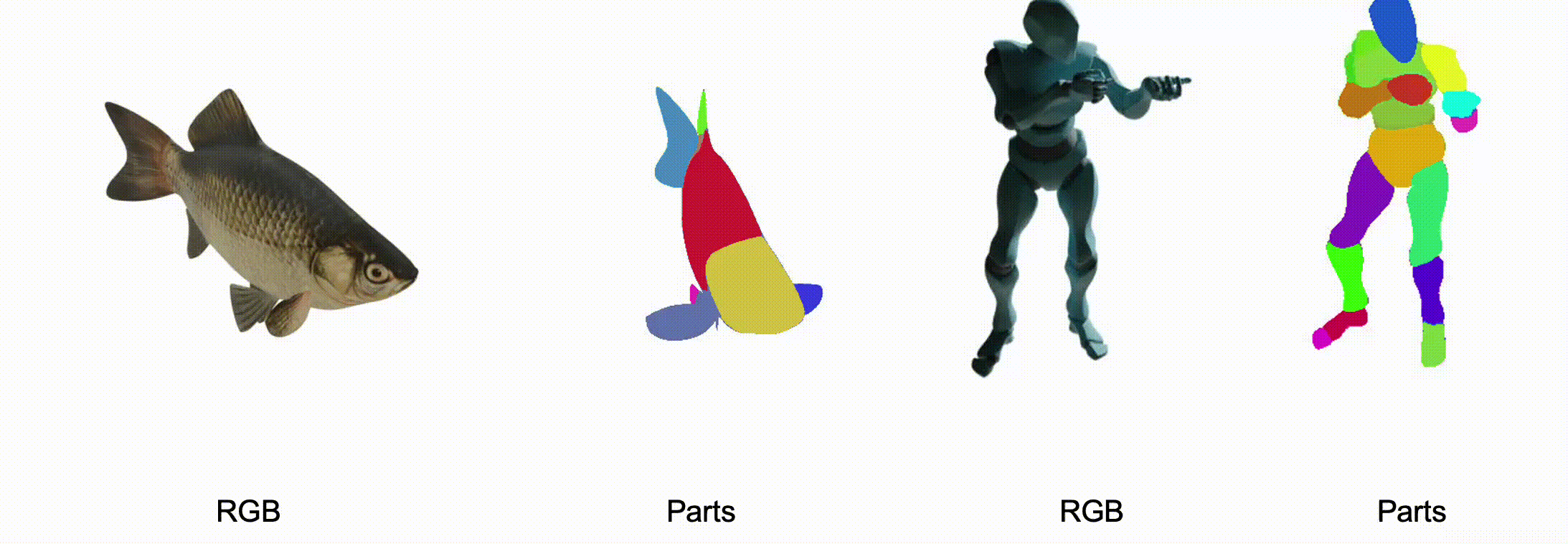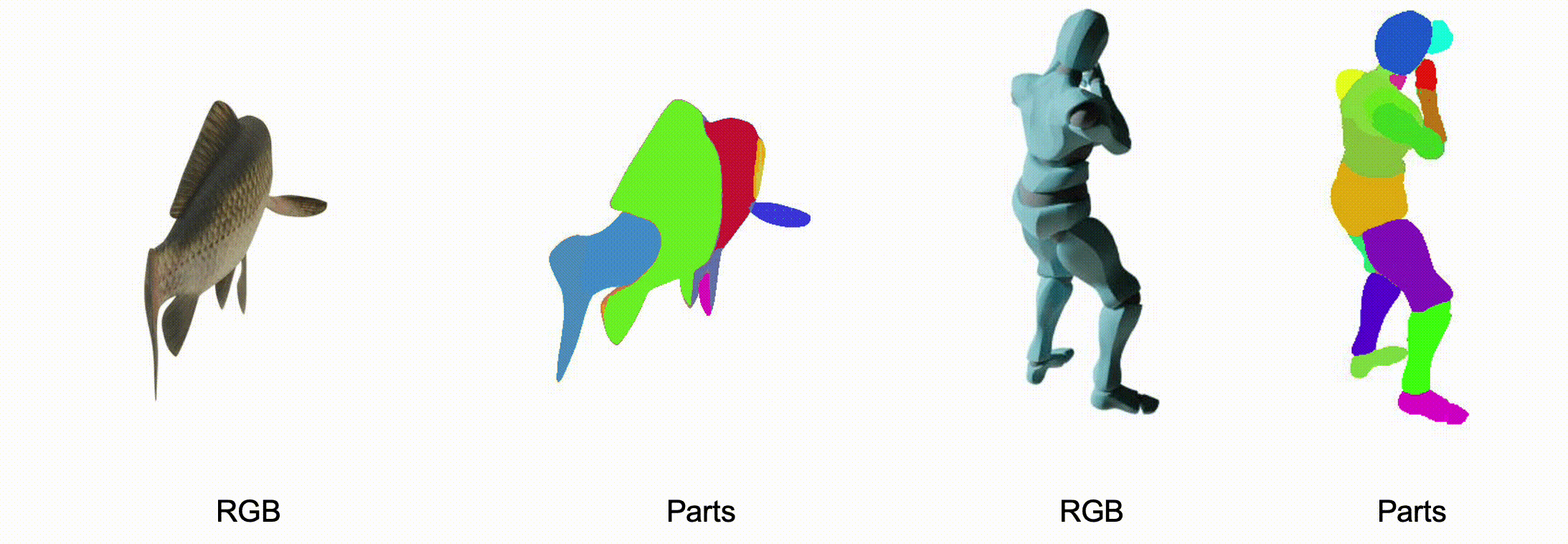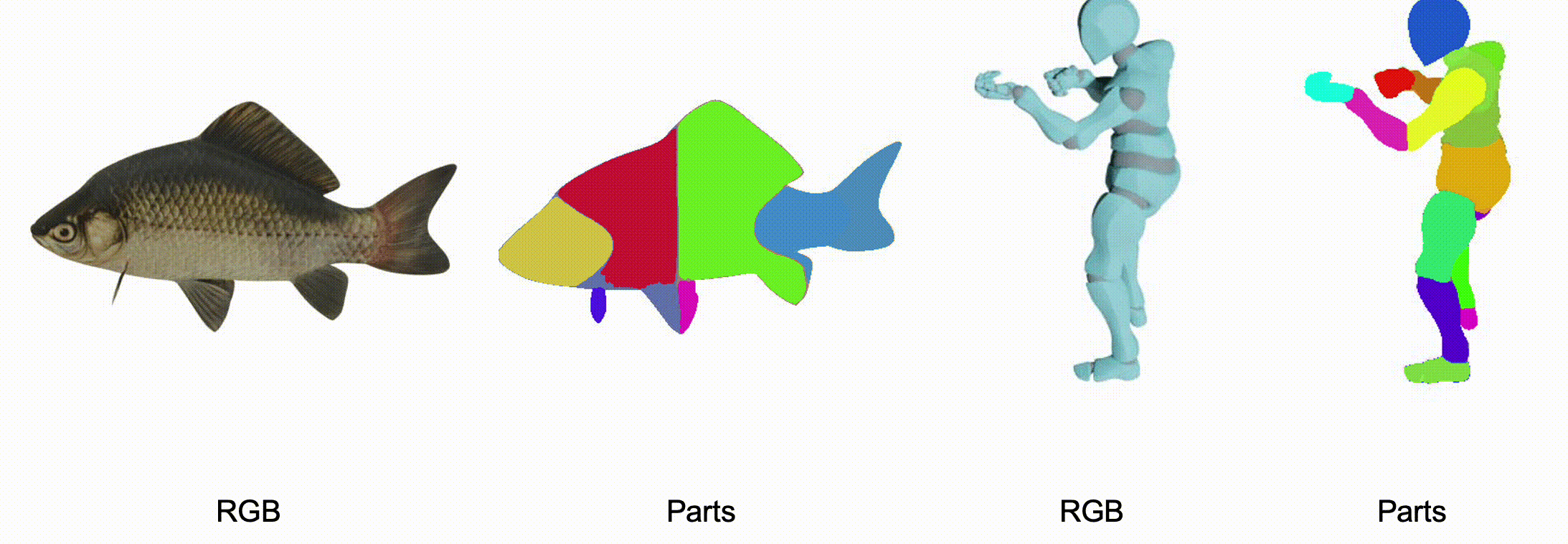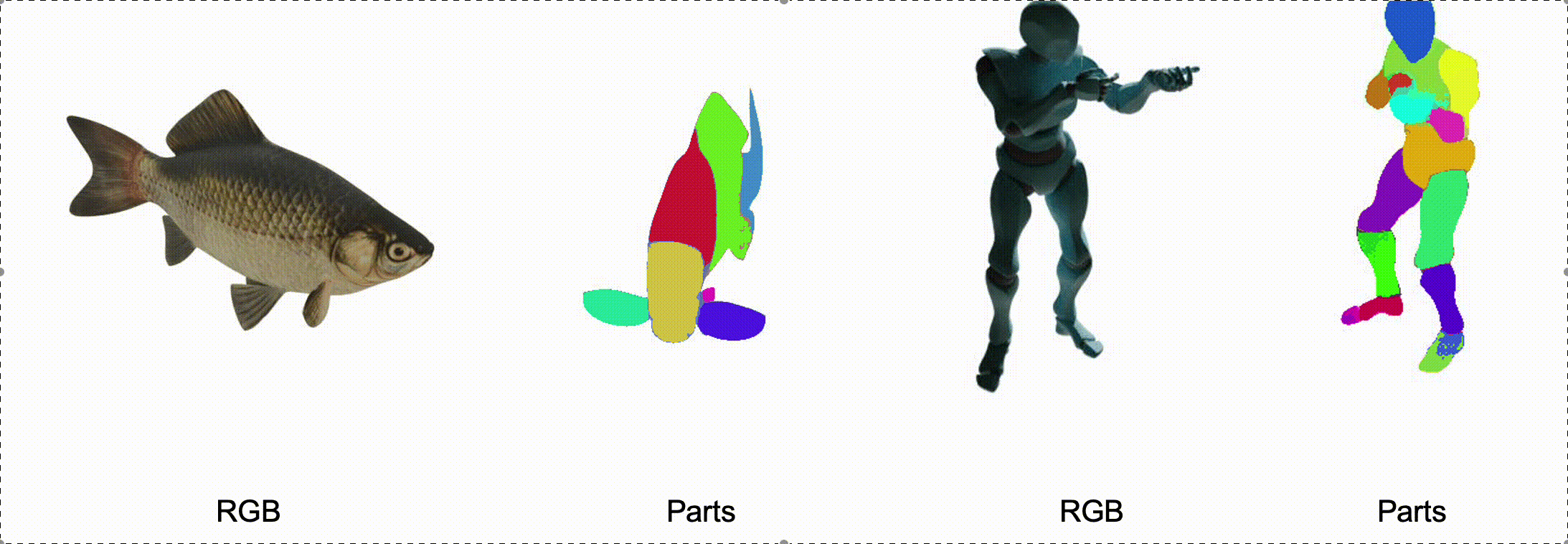
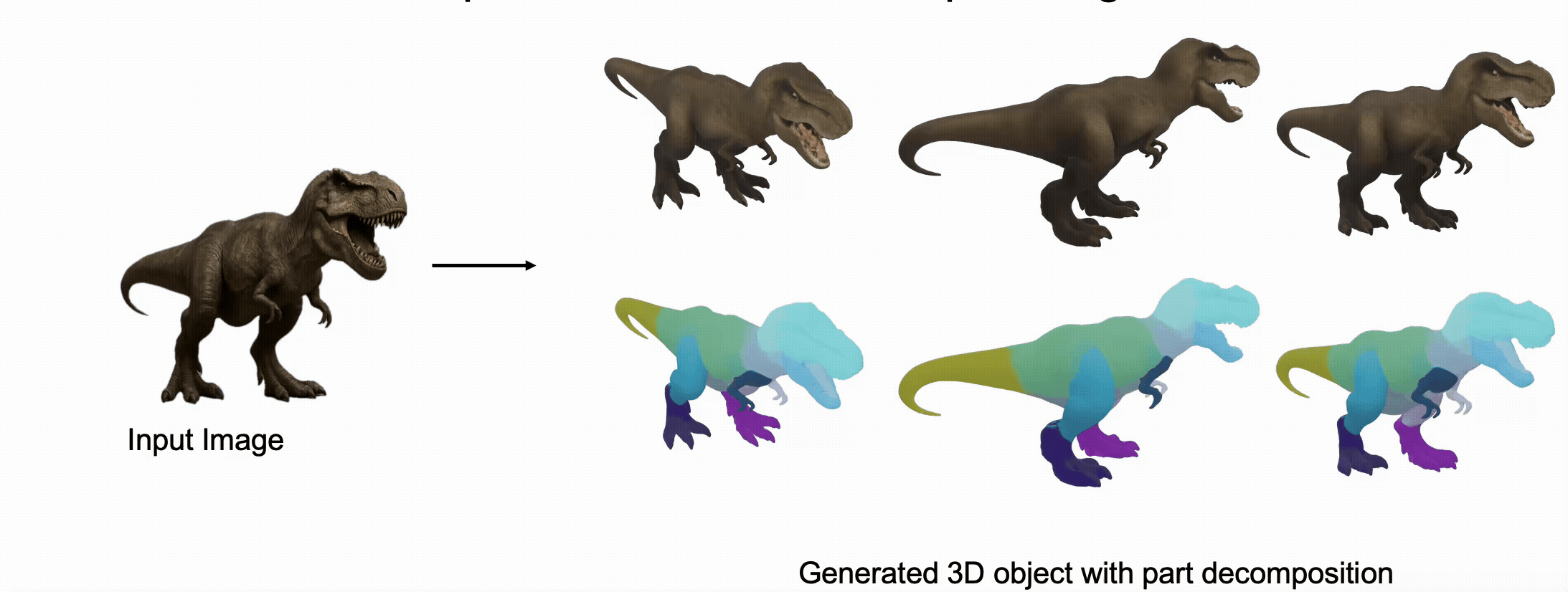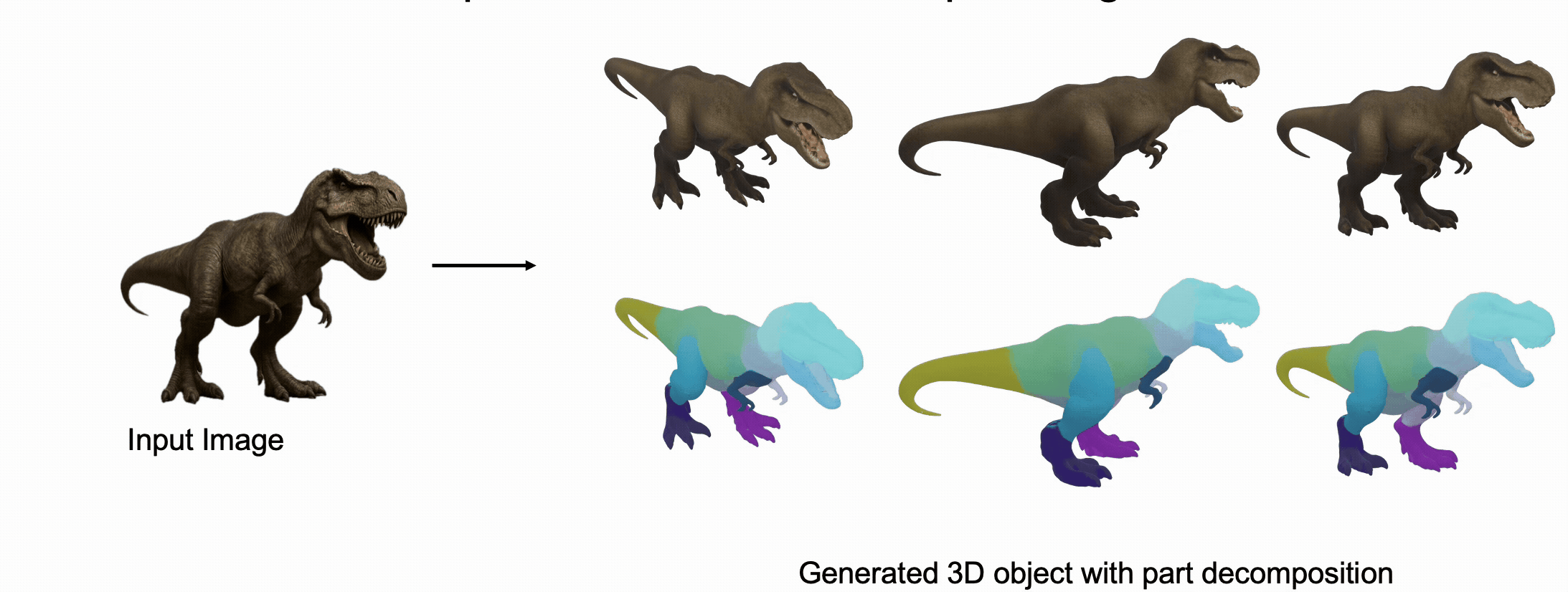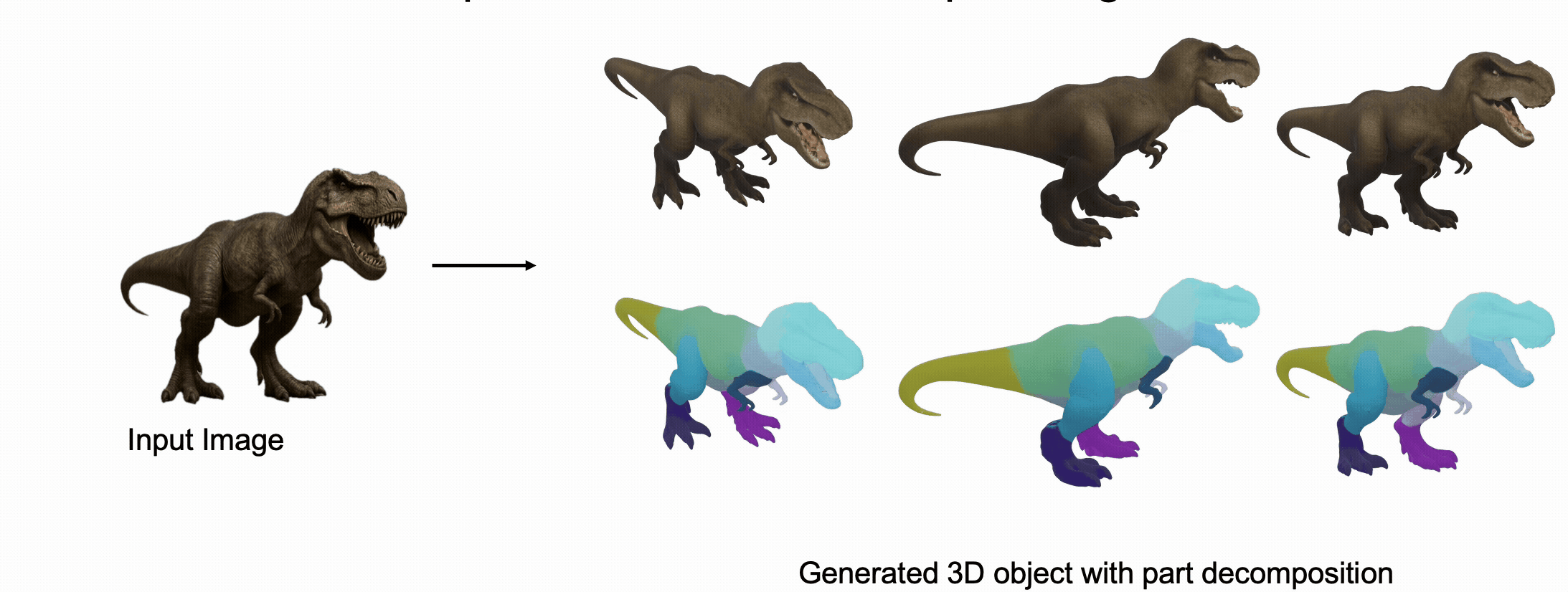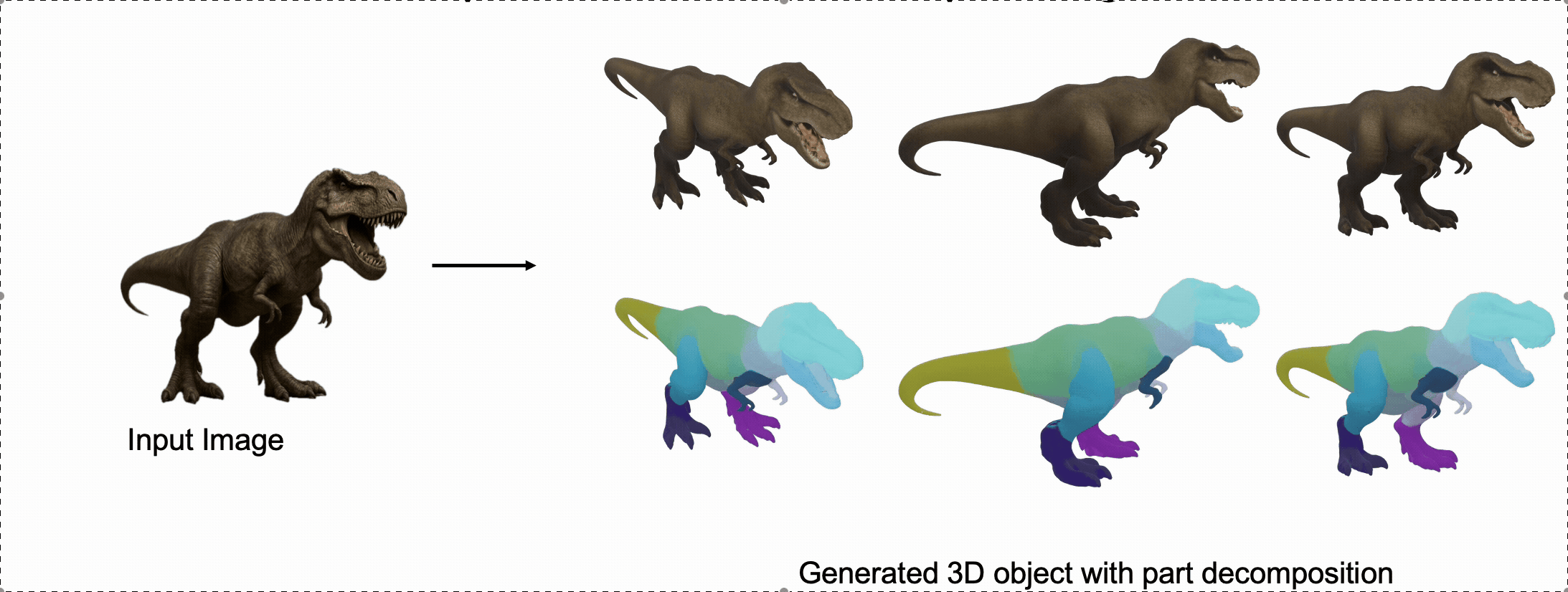
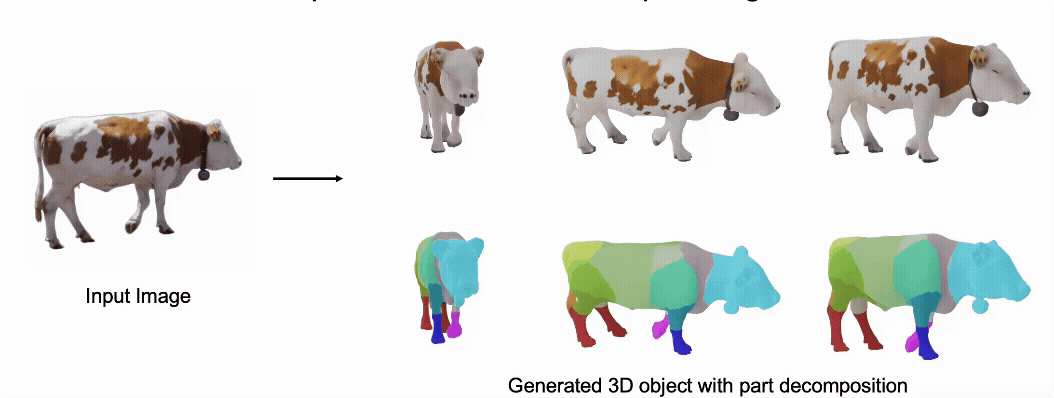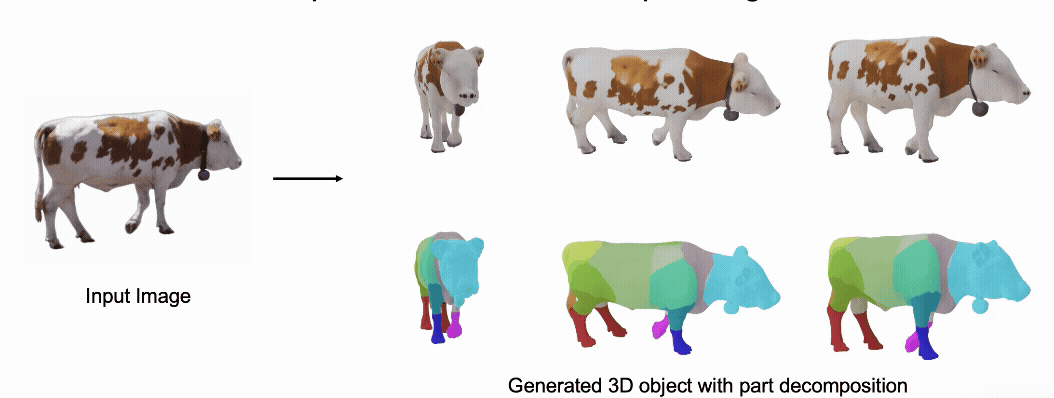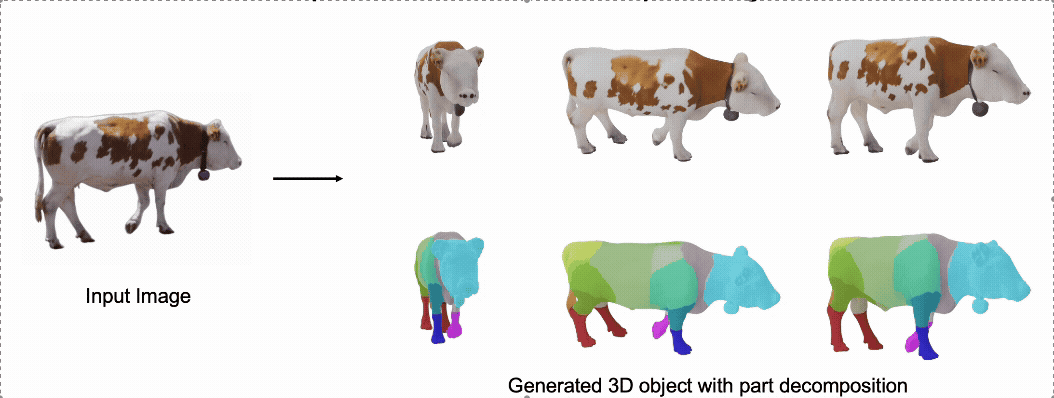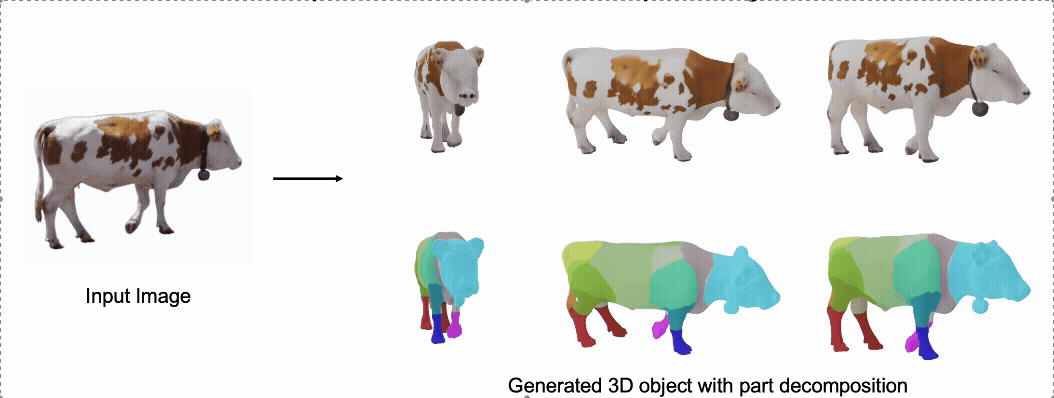
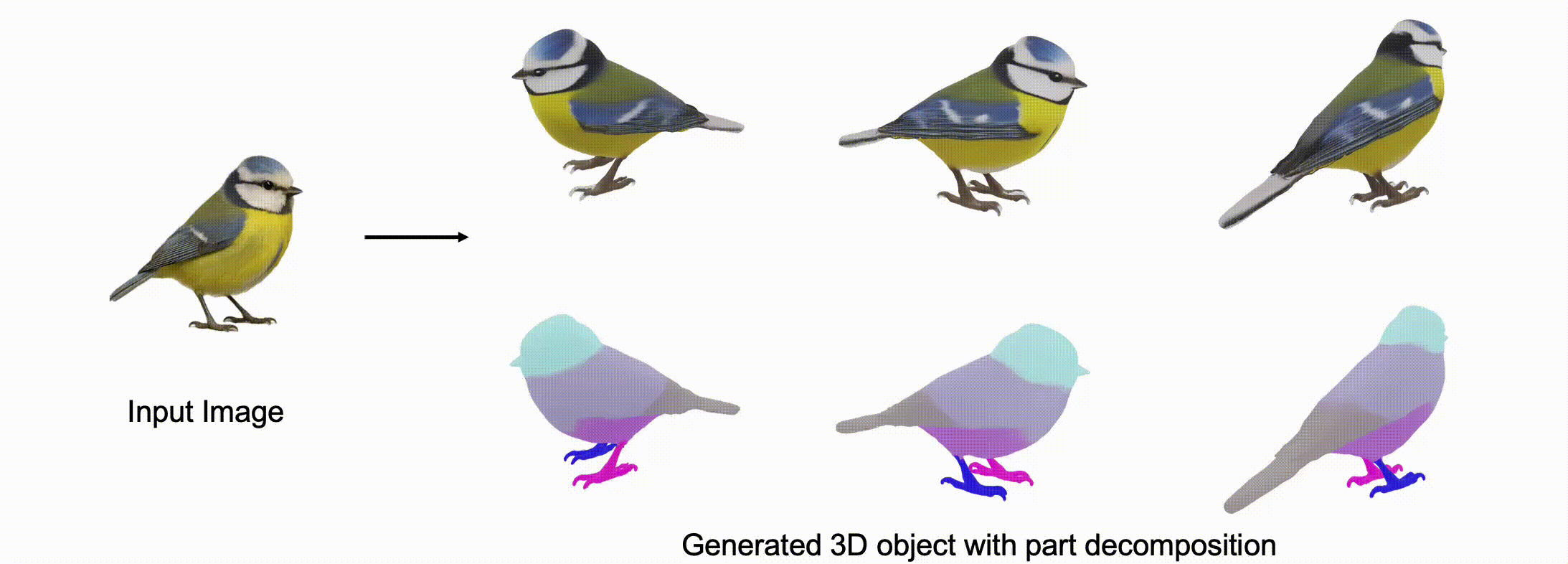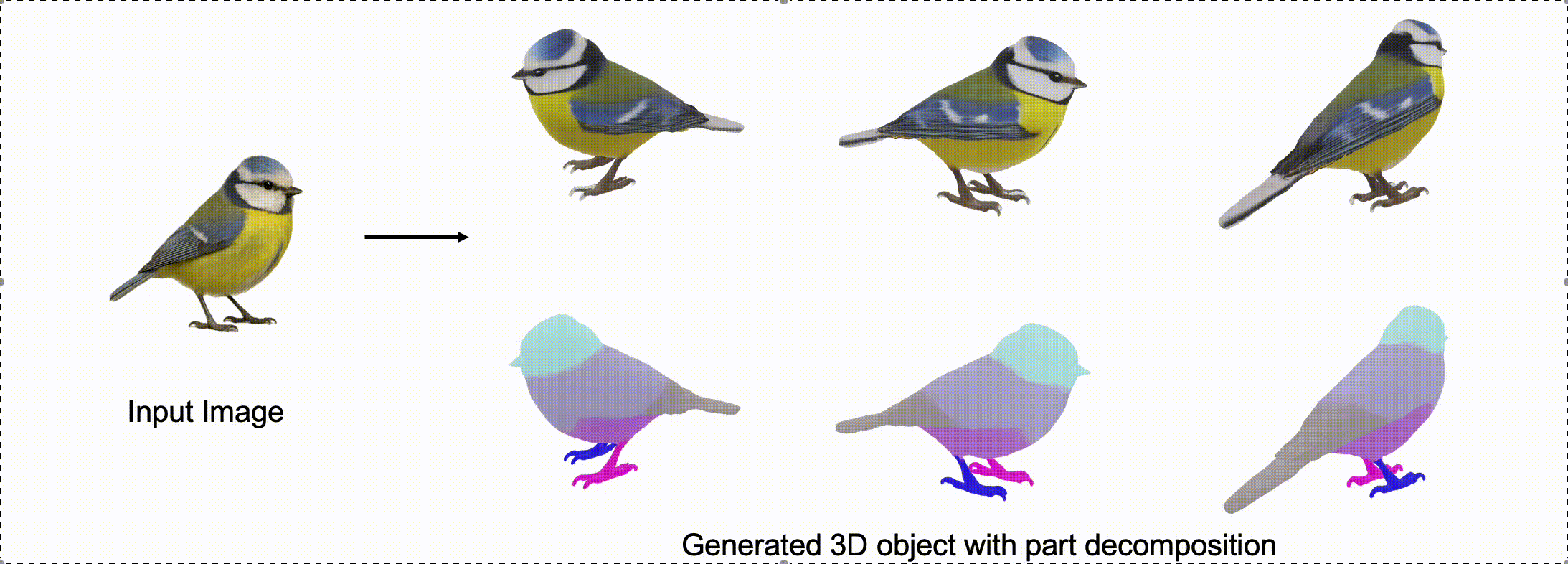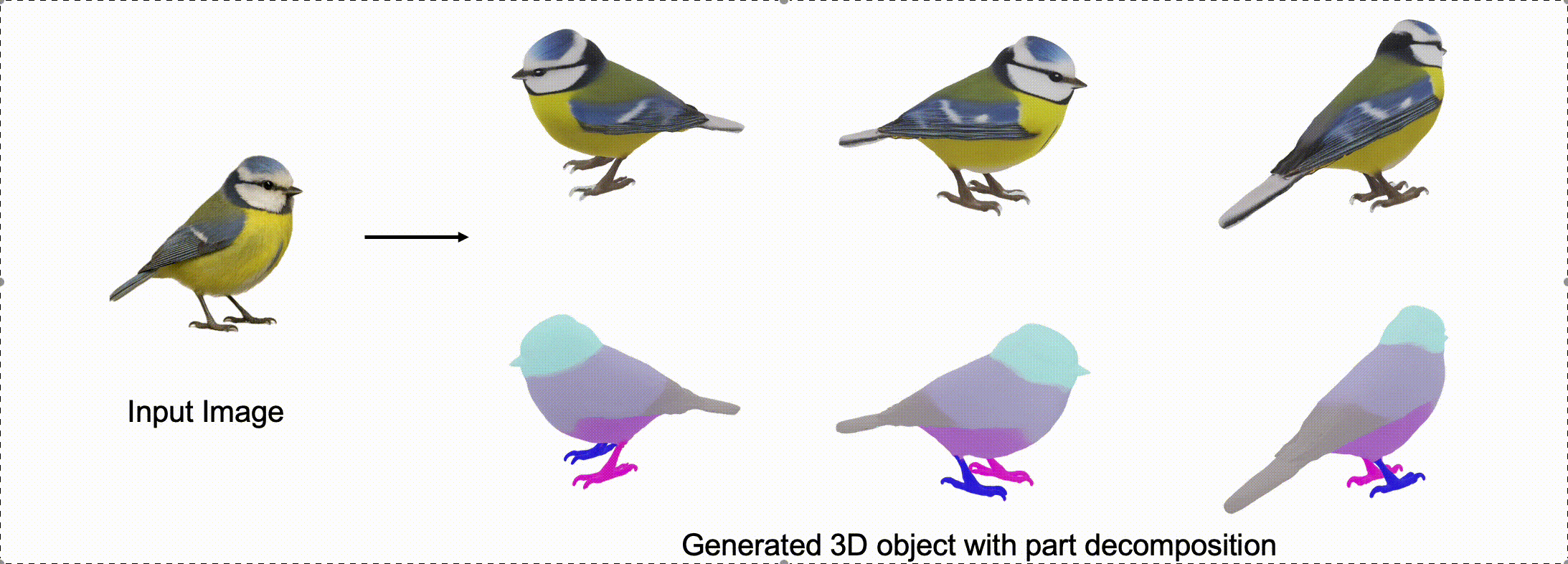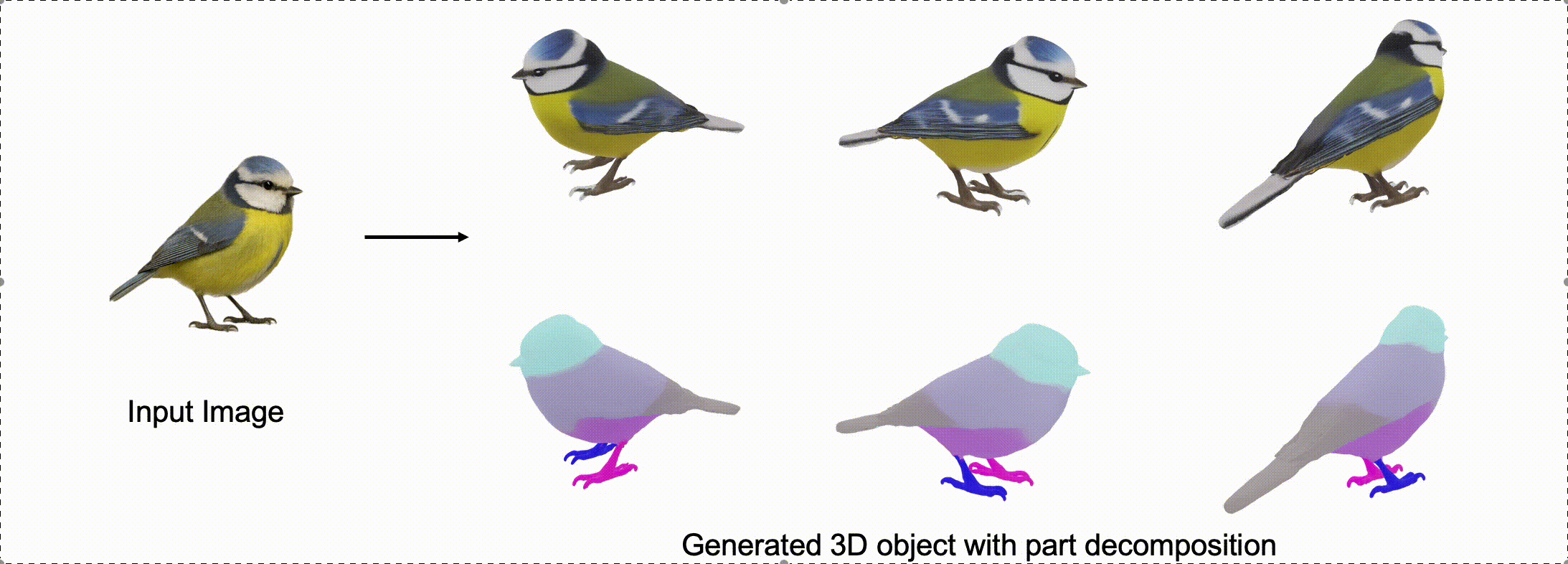



@misc{zhang2025stablediffusion4dmultiview,
title={Stable Part Diffusion 4D: Multi-View RGB and Kinematic Parts Video Generation},
author={Hao Zhang and Chun-Han Yao and Simon Donné and Narendra Ahuja and Varun Jampani},
year={2025},
eprint={2509.10687},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.10687},
}Stable Part Diffusion 4D: Multi-View RGB and Kinematic Parts Video Generation
Hao Zhang1,2,*, Chun-Han Yao1, Simon Donné1, Narendra Ahuja2, Varun Jampani1
1Stability AI 2University of Illinois at Urbana-Champaign


Accepted at
NeurIPS 2025
✨ Spotlight
*Work done as a research intern at Stability AI